ChatGPT A Réussi Le Test De Turing. Comment Les Intelligences Artificielles « Fortes » Émergeront-Elles Désormais ?
Une intelligence artificielle forte (IAF) apparaîtra-t-elle soudainement, ou les scientifiques auront-ils la possibilité de la prévoir et d’avertir le monde ? C’est une question qui a récemment suscité beaucoup d’attention avec l’émergence de grands modèles linguistiques tels que ChatGPT, qui ont acquis d’immenses nouvelles capacités à mesure que leur taille a augmenté. Certaines découvertes évoquent le concept d' »émergence », un phénomène selon lequel les modèles d’IA acquièrent de l’intelligence de manière brusque et imprévisible. Cependant, une étude récente qualifie ces cas de « mirages » — des artefacts résultant de la manière dont les systèmes sont testés — et suggère que les capacités innovantes se développent plutôt de manière plus progressive.
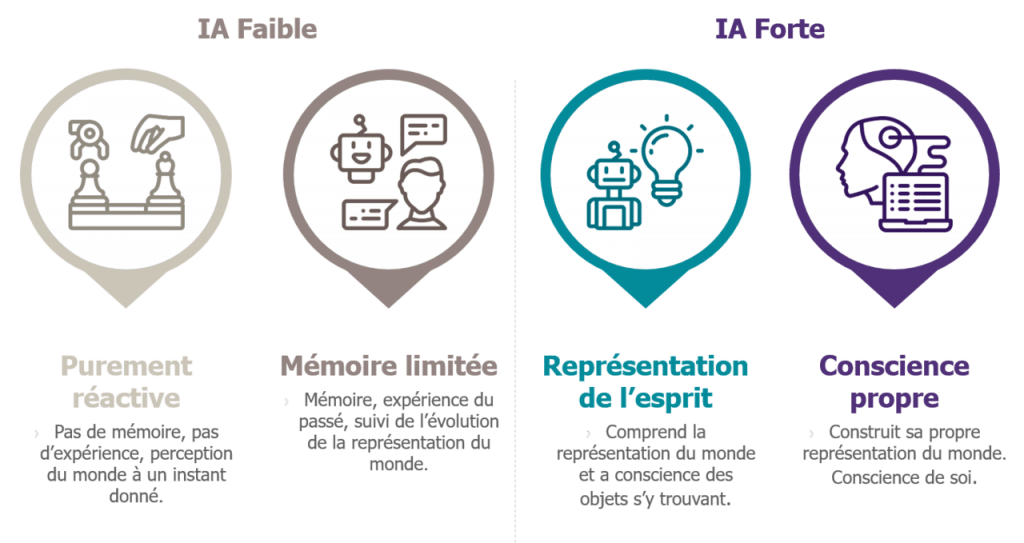
/// Certains chercheurs pensent que l’IA pourrait éventuellement atteindre une intelligence forte, égalant voire dépassant les capacités humaines dans la plupart des tâches. ///
La règle du « plus c’est grand, mieux c’est ! »
Les modèles de langage de grande envergure sont couramment entraînés à l’aide de vastes corpus textuels ou d’autres sources d’information, qu’ils utilisent pour générer des réponses réalistes en anticipant les éléments suivants. Même sans un entraînement explicite, ces modèles parviennent à accomplir des tâches telles que la traduction de langages, la résolution de problèmes mathématiques, ainsi que la création de poésie ou de code informatique. La performance de ces modèles s’améliore proportionnellement à leur taille, certains dépassant même la barre des cent milliards de paramètres ajustables. Certains chercheurs émettent l’hypothèse que ces outils pourraient éventuellement atteindre une intelligence artificielle fortes (IAF), les plaçant au niveau, voire au-delà, des performances humaines dans la plupart des domaines.
La nouvelle recherche a testé les revendications d’émergence de plusieurs manières. Dans une approche, les scientifiques ont comparé les capacités de quatre tailles du modèle GPT-3 d’OpenAI à additionner des nombres à quatre chiffres. En examinant l’exactitude absolue, les performances différaient entre la troisième et la quatrième taille du modèle, passant de près de 0% à près de 100%. Cependant, cette tendance est moins extrême si l’on considère le nombre de chiffres correctement prédits dans la réponse. Les chercheurs ont également constaté qu’ils pouvaient atténuer la courbe en donnant aux modèles beaucoup plus de questions de test — dans ce cas, les modèles plus petits répondaient correctement certaines fois.
Ensuite, les chercheurs ont examiné les performances du modèle linguistique LaMDA de Google sur plusieurs tâches. Les tâches pour lesquelles il a montré un saut soudain d’intelligence apparente, telles que la détection de l’ironie ou la traduction de proverbes, étaient souvent des tâches à choix multiples, avec des réponses évaluées de manière discrète comme correctes ou incorrectes. En revanche, lorsque les chercheurs ont examiné les probabilités que les modèles attribuaient à chaque réponse — une mesure continue — les signes d’émergence ont disparu.
Enfin, les chercheurs se sont tournés vers la vision par ordinateur, un domaine où il y a moins de revendications d’émergence. Ils ont entraîné des modèles à compresser puis à reconstruire des images. En fixant simplement un seuil strict de correction, ils pouvaient induire une émergence apparente. « Ils ont été créatifs dans la façon dont ils ont conçu leur enquête », déclare Yejin Choi, informaticienne à l’Université de Washington à Seattle, qui étudie l’IA et le bon sens.
Rien n’est impossible
Sanmi Koyejo, co-auteur de l’étude et informaticien à l’Université Stanford à Palo Alto, en Californie, indique qu’il n’était pas déraisonnable pour les individus d’envisager l’émergence, étant donné que certains systèmes présentent des « changements de phase » abrupts. Il souligne néanmoins que l’étude ne peut pas exclure entièrement cette possibilité, que ce soit dans le contexte des grands modèles de langage ou des systèmes futurs. Il ajoute que « les études scientifiques jusqu’à présent suggèrent fortement que la plupart des aspects des modèles linguistiques sont en effet prévisibles ».
Raji exprime sa satisfaction à l’égard de l’attention accrue accordée par la communauté à l’évaluation comparative plutôt qu’au développement d’architectures de réseaux neuronaux. Elle encourage les chercheurs à aller plus loin et à évaluer dans quelle mesure les tâches sont applicables dans des déploiements réels. Par exemple, réussir l’examen LSAT pour les aspirants avocats, comme GPT-4.5 l’a fait, signifie-t-il qu’un modèle peut agir comme un assistant juridique ?
Ces travaux ont également des implications pour la sécurité et la politique de l’IA. Raji souligne que « la communauté de l’IAG a tiré parti de l’affirmation des capacités émergentes ». Une crainte injustifiée pourrait entraîner des réglementations excessives ou détourner l’attention de risques plus urgents. « Les modèles montrent des améliorations, et ces progrès sont bénéfiques », précise-t-elle. « Cependant, ils ne s’approchent pas encore de la conscience. »
ChatGPT 4.5 est le seul à avoir passé le test... Les autres Chabots ont échoués...
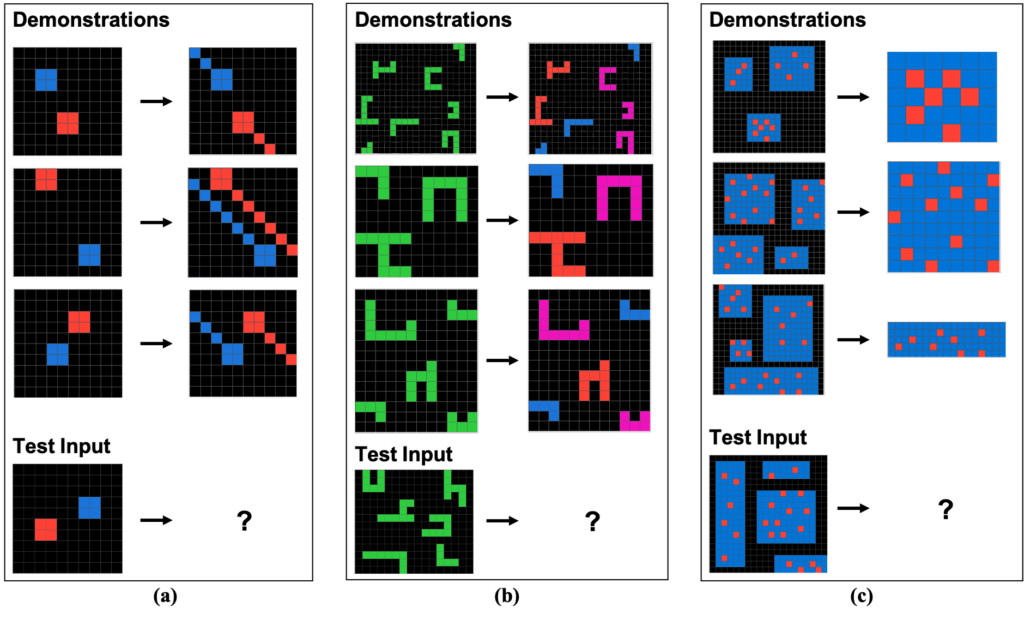
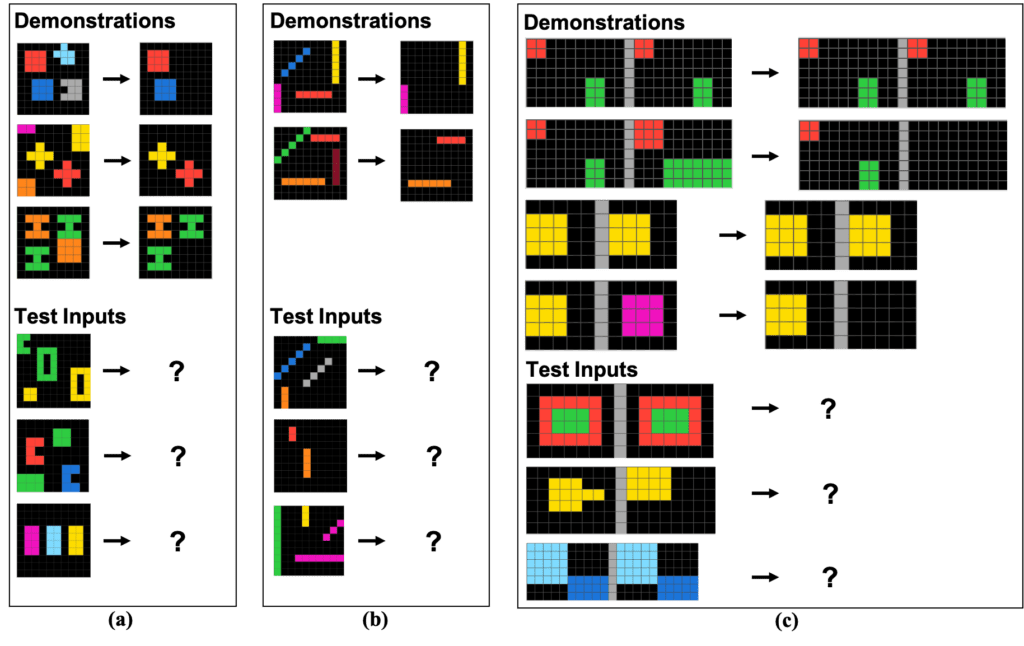
/// Exemples de tâches ARC provenant de F. Chollet [The Abstraction and Reasoning Corpus (ARC)]. Chaque tâche se compose d’un ensemble de démonstrations de tâches — La transformations entre des grilles colorées suivent la même règle abstraite — et une seule entrée de test. Le rôle du résolveur est de générer une nouvelle grille résultant de l’application de la règle abstraite à l’entrée de test. ///
ChatGPT 4.5 a réussi le test de Turing
Les meilleurs systèmes d’intelligence artificielle (IA) au monde peuvent réussir des examens difficiles, rédiger des essais convaincants et converser de manière si fluide que beaucoup trouvent leurs productions indiscernables de celles des humains. Qu’est-ce qu’ils ne peuvent pas faire ? Résoudre des énigmes logiques visuelles simples.
Dans un test composé d’une série de blocs colorés disposés sur un écran, la plupart des gens peuvent repérer les schémas de connexion. Cependant, GPT-4, la version la plus avancée du système d’IA derrière le chatbot ChatGPT et le moteur de recherche Bing, ne réussit à peine qu’un tiers des énigmes dans une catégorie de schémas et aussi peu que 3 % correctement dans une autre, selon un rapport publié par des chercheurs en mai1.
L’équipe derrière les énigmes logiques vise à fournir une meilleure référence pour évaluer les capacités des systèmes d’IA, tout en contribuant à résoudre un casse-tête concernant les grands modèles linguistiques (LLMs) tels que GPT-4. Testés d’une manière, ils réussissent aisément ce qui était autrefois considéré comme des prouesses marquantes de l’intelligence artificielle. Testés d’une autre manière, ils semblent moins impressionnants, présentant des angles morts évidents et une incapacité à raisonner sur des concepts abstraits.
« Les personnes dans le domaine de l’IA ont du mal à évaluer ces systèmes », déclare Melanie Mitchell, informaticienne au Santa Fe Institute au Nouveau-Mexique, dont l’équipe a créé les énigmes logiques (voir ‘Un test de pensée abstraite qui bat les machines’).
Un examen de pensée abstraite, le test ConceptARC, s’est avéré être une épreuve que les systèmes d’intelligence artificielle n’ont pas encore réussi à surpasser à un niveau équivalent à celui des performances humaines. Ce casse-tête logique demande aux solveurs de démontrer la manière dont les motifs de grille évoluent après avoir été témoins de plusieurs démonstrations d’un concept abstrait sous-jacent. Deux tâches d’exemple basées sur le même concept sous-jacent sont présentées ci-dessous. Pouvez-vous les résoudre ?

Nicolas Dumont
Annonces PARTENAIRES